

The core idea
The framework described here is a repeatable scoring method for evaluating competing improvements. It works by defining what performance dimensions matter, identifying which audience groups (or cohorts) are affected, capturing how much each dimension matters to each cohort, and scoring how much any given improvement moves the needle on each dimension. The result is a single comparable value for each improvement-cohort pair, derived from structured judgement rather than gut feel.
The key principle is the separation of two questions that are usually conflated: how much does this improvement help, and how much does that help actually matter? A change that dramatically improves something nobody cares about should not outrank a modest change to something critical. Weighting makes this distinction explicit.
The building blocks
Performance dimensions are the measurable aspects of an experience that matter. In a health care context, examples might include feeling heard, confidence in next steps, and a sense of control. In an employee experience or workplace change, they might be feeling consulted, psychological safety, and clarity of expectations. The list should be short (five to eight dimensions is typical), shared across all assessments in a given programme, and stable enough that comparisons across rounds are meaningful.
Cohorts are the distinct audience groups who experience the service or product. What matters to people with long-term health conditions is not the same as what matters to people focussed on optimising their fitness. The framework captures this by assigning each cohort its own set of dimension weights. For any given cohort, the weights across all dimensions sum to 100. A cohort that cares deeply about reliability but barely notices wayfinding will assign very different weights from one where accessibility is everything.
Scoring an improvement
For each dimension, the current state of the experience is rated on a simple five-point scale. The expected post-improvement state is rated the same way. The difference between the two is the lift, how much the improvement moves the needle.
Critically, these scores don't have to be assumed. They can be tested. Taking proposed improvements to customers and assessing their impact on the experience before and after produces scores grounded in evidence rather than internal opinion. That step alone significantly increases the accuracy and credibility of the prioritisation.
The same improvement will produce different value scores for different cohorts, because each cohort weights the dimensions differently. Without making that explicit, decisions default to whoever argues loudest.
What gap analysis adds
A good headline score can mask a persistent problem. An improvement that delivers strong value overall might still leave one dimension in a poor state. Gap analysis is the discipline of separately flagging dimensions that start below a threshold and remain below it after the improvement is applied. This stops a high overall value score from implying that everything is fine when one aspect of the experience is still failing a particular cohort.
Seeing the whole picture
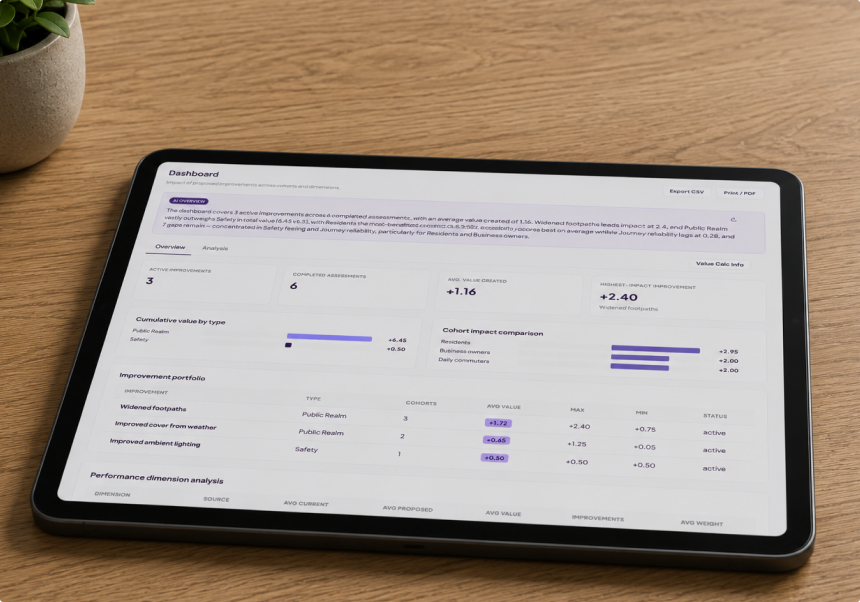
Once multiple improvements have been scored across multiple cohorts, the numbers can be aggregated in several useful ways. Improvements can be ranked by total value created across all cohorts. Value can be summed by cohort to reveal which groups are consistently well served and which are consistently underserved. Dimension-level scores across all improvements can identify systemic weaknesses that no single improvement addresses.
Better decisions, and ones you can defend
The framework does not replace human judgement. It structures it. Every weight reflects a deliberate assessment of what matters to a specific group. Every score reflects an honest appraisal of current and expected performance.
When prioritisation decisions are made this way, they become explainable. The team can say: we chose this improvement because it creates the highest value for the cohorts we are most accountable to, and here are the assumptions behind that. Stakeholders who disagree can identify exactly where they disagree. That is a far more productive conversation than arguing about whose intuition to trust.
The framework is most useful when a team faces a genuine backlog of options and a finite capacity to act, when different stakeholders have genuinely different priorities, or when accountability for decisions extends beyond the immediate team. It is also useful as a before-and-after tool: score the same improvements in successive rounds using the same dimensions and cohorts, and the data builds into a record of how thinking has evolved and whether the assumptions behind earlier decisions held up.



